OT Disaster Recovery: enabling the safe, structured, and reliable recovery of industrial operations


Introduction
In a previous blog, I introduced Operational Technology (OT) which focuses on the technologies used to monitor and control physical processes and industrial assets. That article also explored the key differences between OT and Information Technology (IT) environments.From an operational perspective, all organisations should have plans in place to ensure Service Continuity in the event of disruptions that impact normal operations.
Operational disturbances can occur for many reasons and may interrupt the smooth running of an asset. If not managed correctly, these incidents can quickly escalate into larger operational or safety issues.
In some cases, the disruption may be severe enough to force a shutdown of operations. When this happens, organisations must follow structured processes or standard operating procedures (SOPs) to restart systems safely, securely, and in a controlled manner.
This is where Disaster Recovery begins.
What is Disaster Recovery?
Disaster Recovery (DR) refers to the structured process of restoring operational systems and services after a major disruption that has stopped production or plant operations.Disaster Recovery is a component of a wider Disaster Management Cycle. While recovery focuses on restoring operations, organisations must also consider how they respond to incidents, prepare for disruption, and mitigate future risks.
Together, these capabilities form a continuous cycle of Operational Resilience.

- Response – Is the bridge between disruption and recovery—ensuring safety, containment, and control before restoration begins.
- Recovery – The structured restoration of control systems, operational data and industrial processes.
- Mitigation – focuses on reducing the likelihood or impact of future disruptions. DR also acts as a feedback loop into mitigation—using lessons learned to strengthen systems and reduce future failures.
- Preparedness – Being ready before disruption occurs.
In an OT environment, disaster recovery focuses on restoring control systems, operational data, and industrial processes so that production can safely resume.
Why OT Disaster Recovery is Fundamentally Different from IT
Disaster Recovery in Operational Technology (OT) environments is fundamentally different from traditional IT recovery. In IT environments, recovery is typically focused on restoring systems, applications, and data - often prioritising speed and availability.In OT environments, recovery is not just about restoring systems—it is about restoring physical processes safely.
Key differences include:
- Safety-Critical Operations - In OT, incorrect recovery actions can result in equipment damage, environmental impact, or safety incidents.
- Controlled Restart Requirements - Industrial systems cannot simply be “switched back on.” They require sequenced, validated, and controlled restart procedures.
- Physical Process Dependencies - Systems are tightly coupled with physical assets (e.g. pumps, reactors, conveyors), meaning recovery must consider real-world conditions.
- Downtime Impact is Immediate and Tangible - Production loss, safety risks, and operational disruption occur instantly—not just service degradation.
- Legacy and Specialist Systems - OT environments often rely on specialised, vendor-specific systems that are harder to restore and validate.
As a result, OT Disaster Recovery must be:
- Structured
- Tested
- Safety-led
- Operationally aligned
Common Failure Points During OT System Restart
Restarting industrial systems after a disruption is one of the most critical and high-risk phases of Disaster Recovery. Even when systems have been restored, failures during restart can lead to extended downtime, equipment damage, or safety incidents.
Some common failure points include:
- Control System Synchronisation Issues
- Controllers, HMIs, and servers may be:
- Out of sync
- Running mismatched configurations
- This can result in:
- Incorrect process control behaviour
- Alarm floods or system instability
- Controllers, HMIs, and servers may be:
- Loss or Corruption of Operational Data
- Historian or configuration data may be:
- Incomplete
- Corrupted
- This impacts:
- Visibility
- Decision-making during retstart
- Historian or configuration data may be:
- Sequence of Startup Not Followed
- Industrial processes require strict startup sequencing
- Incorrect order can:
- Damage equipment
- Cause process imbalance
- Trigger safety trips
- Field Device and Instrumentation Failures
- Sensors, actuators, or PLC I/O may:
- Fail to respond
- Provide incorrect readings
- This leads to:
- Unsafe or unreliable operations
- Sensors, actuators, or PLC I/O may:
- Network and Communication Breakdowns
- OT networks may not fully recover:
- Roles may be unclear
- Decisions may be rushed
- Result:
- Loss of communication between systems
- OT networks may not fully recover:
- Human Factors and Role Confusion
- During high-pressure recovery
- Roles may be unclear
- Decisions may be rushed
- Leading to:
- Errors in execution
- Delayed Recovery
- During high-pressure recovery
- Incomplete System Validation
- Systems are started without:
- Full functional checks
- Safety Validation
- This increases the risk of:
- Secondary failures
- Systems are started without:
What Does a Structured Recovery Approach Look Like in Practice?
A structured Disaster Recovery approach is not just about having a documented plan, it is about executing recovery in a controlled, sequenced, and validated manner.In OT environments, recovery typically follows a defined progression that is made up of the following actions:
- Stabilisation and Safety Assurance
- Confirm plant is in a safe state
- Isolate affected systems
- Ensure no ongoing hazards
- System Integrity Verification
- Validate:
- Control system configurations
- Network availability
- Data integrity
- Validate:
- Infrastructure and Network Recovery
- Restore:
- Servers
- Networks
- Communications
- Restore:
- Control System Restoration
- Bring back:
- PLCs / DCS / SCADA
- Ensure:
- Synchronisation
- Correct configurations
- Bring back:
- Field Device and Process Validation
- Check:
- Sensors
- Actuators
- Instrumention
- Check:
- Controlled Process Restart
- Follow defined statrtup sequences
- Gradually re-introduce operations
- Monitoring and Stabilisation
- Observe system behaviour
- Validate performance
- Address anomalies
- Post-Recovery Review
- Capture lessons learned
- Feed into mitigation and improvement
What are the causes of a Disaster Recovery event?
There are many potential causes of a Disaster Recovery event. These may originate from:- Operational failures
- External threats
- Environmental or natural events
- Site-wide power failure
- Natural disasters such as flooding or extreme weather
- Cyberattacks (e.g. ransomware)
- Central control system failures
- Data historian corruption or loss
- Network infrastructure failures
How can organisations prepare for a such an event scenario?
Organisations can prepare for potential disruptions by developing a Disaster Recovery Plan (DRP). A DRP is a living document that defines the procedures, roles, and responsibilities required to restore operations following a disaster scenario.
A well-developed DRP typically includes:
- Clearly defined roles and responsibilities
- Recovery procedures for different disaster scenarios
- Communication plans
- Defined recovery objectives and timelines
Five Key Steps to Developing an effective Disaster Recovery Plan
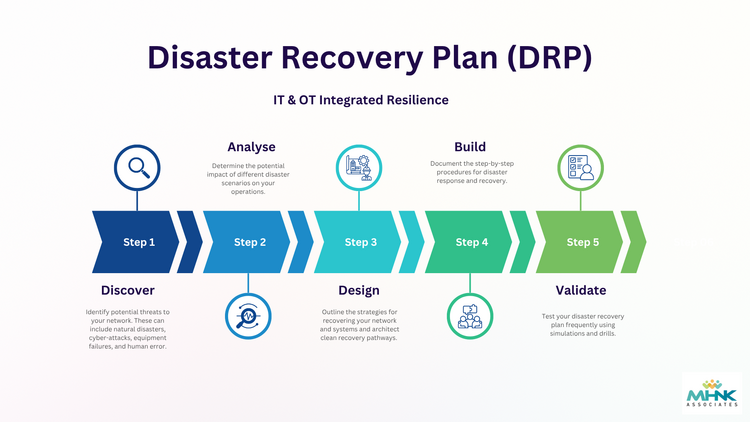
Step 1. Discover
In the initial phase, organisations identify critical assets and potential threats to their OT systems and operational infrastructure.This stage includes identifying possible disruption scenarios and understanding which systems are essential for maintaining operations.
Step 2. Analyse
During this phase, organisations perform a Business Impact Assessment (BIA) to understand how each disruption scenario could affect operations.The BIA helps determine:
- Critical systems and assets
- Operational dependencies
- Acceptable downtime limits
Step 3. Design
In the design phase, organisations develop recovery strategies to restore operations and OT systems.This may include:
- Backup strategies
- Redundant infrastructure
- Recovery procedures for control systems and networks
Step 4. Build
During the build phase, the recovery strategies are documented in detail.This includes creating:
- Step-by-step recovery procedures
- Roles and responsibilities for incident response
- Communication and escalation plans
Step 5. Validate
A Disaster Recovery plan is only effective if it has been tested and validated.In this phase, organisations conduct:
- Tabletop exercises
- Simulated disaster scenarios
- Operational drills
Why is a Disaster Recovery Plan important?

A Disaster Recovery Plan (DRP) plays a critical role in restoring operations safely, efficiently, and with minimal disruption.
Much like emergency procedures used during safety incidents, a DRP provides clear instructions on:
- Managed and reliable operations recovery that consider process RTOs and RPOs
- What actions need to be taken
- Who is responsible for executing them
- How communication should be managed during the recovery process
RTO stands for Recovery Time Objective which defines the target time for restoring normal operations to prevent critical operational failures.
RPO stands for Recovery Point Objective which determines the frequency of backups, bridging the gap between the last valid backup and the disruption.
In many regulated industries, having a disaster recovery capability is also a requirement to meet compliance and regulatory obligations.
How Do You Know if Your Disaster Recovery Preparation is Effective?
The effectiveness of a Disaster Recovery Plan (DRP) can only be proven through regular testing, capturing lessons learned and continuous improvement.
Organisations should regularly perform:
- Simulation exercises
- Recovery drills
- Scenario-based testing
Testing also helps identify weaknesses in systems, processes, or communication structures that can be improved before a real incident occurs.
Conclusion
Even short operational disruptions affecting critical industrial systems can result in significant production losses. Developing a structured recovery capability ensures that operational systems can be restored in a safe and controlled manner.By developing a structured OT Disaster Recovery Plan, the facility will benefit from:
- Improved preparedness for operational disruptions
- Reduced risk of extended production downtime
- Clearly defined recovery procedures for critical systems
- Improved coordination during recovery events
- Increased confidence in the site’s ability to safely restore operations following a disruption
If your organisation relies on industrial control systems, understanding your disaster recovery readiness is critical.
MHNK Associates offers independent Operational Technology Disaster Recovery Benchmarking to help organisations evaluate recovery capabilities and identify improvement opportunities.
Comments